Writing a simple JSON Parser from scratch in C++
JSON is one of the most common data interchange formats there is. Thankfully, it is also a pretty simple one. I had written a JSON parser in C++ sometime back, and whilst making it I came across a few decisions that were more involved than I thought they would be. So I have decided to write an article around that JSON Parser. While JSON Parsing is simple, writing one would definitely be useful to build more complex parsers, since the general principles are still present.
I would also like to clarify that this is not in full compliance with the JSON spec. It doesn’t handle stuff like escapes in strings, but the basics are there. It is also probably not very efficient, since I wrote most parts with an intention of them being easier to write than for them to be the fastest possible implementation.In addition to this, it expects a correct input JSON and does not give syntax errors.
The JSON spec
Before starting anywhere, let us pull up the JSON spec.
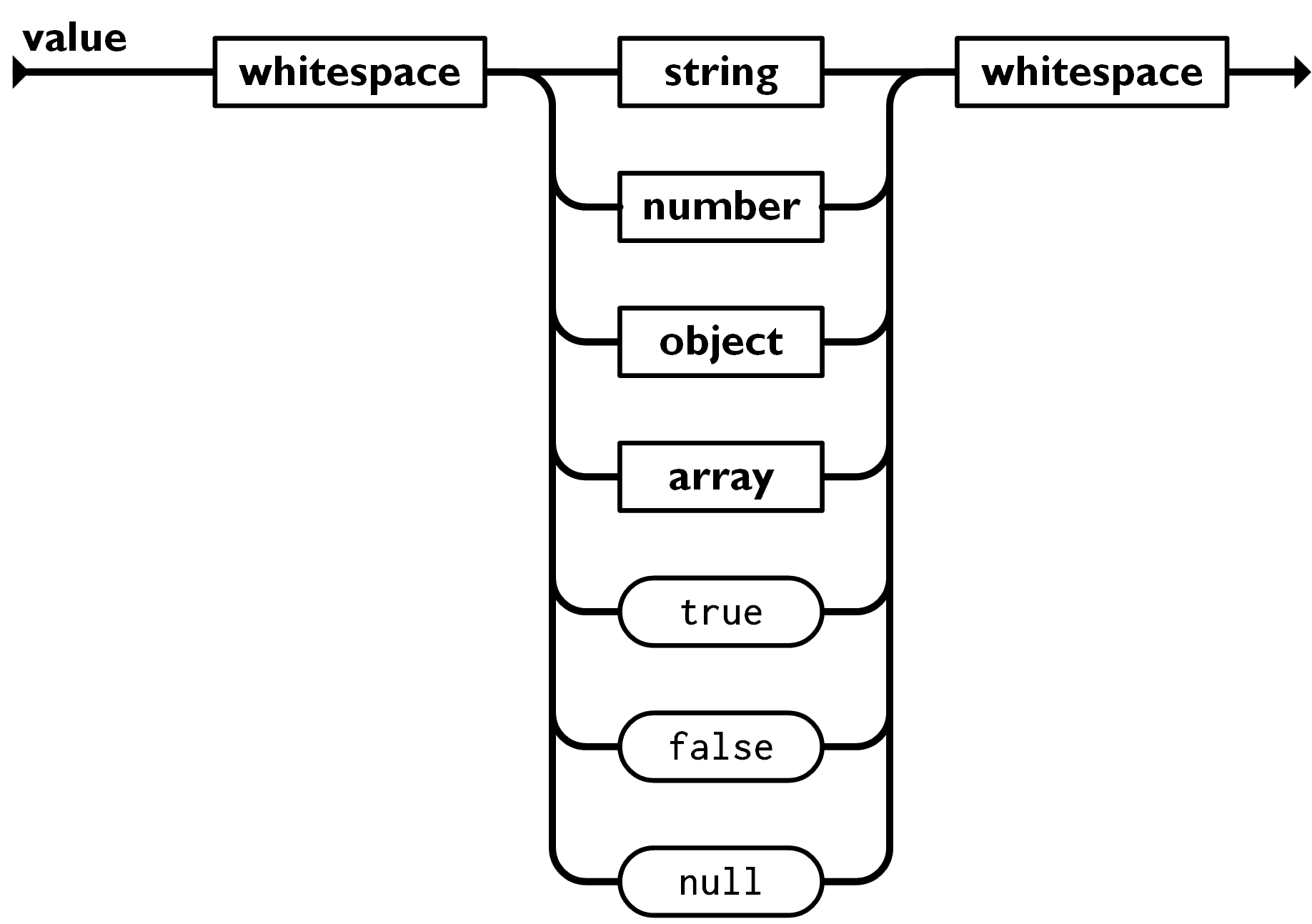
As you can see, it is quite simple. The simple types are:
- Number
- String
- True
- False
- Null
The composite types are:
- Array - A list of JSON values (Note that array itself is a JSON value so you can have an array of arrays)
- Object - It is a set of key-value pairs where you can retrieve any value using its corresponding key.
Choosing a structure for the JSONNode type
The first decision to make when writing a JSON parser is the structure of the JSONNode type which will be holding valid JSON values. I’ll try to explain some possible approaches and see which one is more appropriate.
What do we want from the JSONNode type? We want it to be as space efficient as possible.
The very naive approach
A naive approach would be:
class JSONNodeMostNaive {
JSONObject object;
JSONList list;
std::string s;
float fValue;
bool bValue;
}
This would work, but it is grossly inefficient. Each of these types takes some memory, and for each JSONValue, you have an overhead of the other values.
The size of an empty JSON value would be: 112 bytes.
The naive approach
An approach that is a bit better would be to use pointers, so instead of having to allocate size for each class type, we’ll just have to allocate a constant space for each pointer.
class JSONNodeNaive {
JSONObject *object;
JSONList *list;
std::string *s;
float fValue;
bool bValue;
};
An empty object has size: 32 bytes, a lot better!
Generics? Not.
One of the incorrect paths that you might go down is to think about using generics. At least I’m not aware of a way to use generics in this situation.
You might to think to do generics as:
template<type T>
struct jsonArray{
vector<T>;
}
template<type T>
struct jsonObject{
map<string, T>;
}
The issue with this is that the compiler generates a copy of the struct for each type with the name mangled.
Something like struct jsonObject_type_float
This means that for each type there is a separate jsonObject type and a separate jsonArray type.
So say you have a jsonArray like:
[123, "abc"]
This is a perfectly legal Javascript array. How would you represent this using our jsonArray struct declared above? You can’t, since it is parametrized by type T which can be only one type.
When instantiating jsonArray, you’ll have to tell the compiler what type you’re parametrizing it with like:
jsonArray<int>
or
jsonArray<string>
There is no way for T to be both int and string. But we want T to be one of all possible JSON value types. This is one of those gotchas for those who misunderstand generics (like me). Generics are a way to save time when writing code so that you do not have to write similar implementations for each type. They’re not a way to have the sort of dynamic behavior we’re expecting (to store values of multiple types within the same array)..
My choice: The Union
Coming back to our JSON parser, the way I went with is:
class JSONNode {
enum class Type { OBJECT, LIST, STRING, NUMBER, BOOLEAN, NULL_TYPE};
union Values {
JSONObject *object;
JSONList *list;
std::string *s;
float fValue;
bool bValue;
} values;
Type type;
}
Here, this is similar to our second naive implementation with one optimization: We’re using a union. It’ll take up space of the largest member. Unlike before, we won’t be wasting space by needlessly storing the other types.
NOTE: This is not the canonical C++ way to do this. For that, you can check out std::variant which is a typesafe union.
The size of this is 16 bytes.
Sizes of all three shown:

You might be wondering what JSONObject and JSONList types are.
using JSONObject = std::map<std::string, std::shared_ptr<JSONNode>>;
using JSONList = std::vector<std::shared_ptr<JSONNode>>;
As you can see, they’re just type declarations over standard types.
To access, I have a bunch of utility functions:
- auto returnObject()
- auto returnList()
- auto returnString()
- auto returnFloat();
Let us see the implementation for returnObject(), the rest are quite similar:
auto returnObject() {
if (type == Type::OBJECT) {
return *values.object;
}
throw std::logic_error("Improper return");
}
It doesn’t do much, just some bookkeeping to inform the user whether they’re returning the wrong type and an error thrown i not.
I also have the corresponding setter functions, let us look at setObject:
void setObject(JSONObject *object) {
this->values.object = object;
type = Type::OBJECT;
}
The only issue with this that I perceive is that this puts the burden on the end user to issue the correct function call (i.e they have to know when to call returnObject() instead of returnList()).
You can remove this burden by having some sort of dynamic dispatch but that brings with it its own hurdles. Although the function will be called on the correct object, what set of functions would be common across all JSON value types? I’m not sure, this is something I have to explore further, but currently I do not think that this would work. In any case, I do not think having an idea about the structure about the input is unreasonable.
Tokenization
Now let us look at how we’re going to parse. First we need to tokenize the input. What is tokenization? Well it is the next step after raw text, instead of having a raw stream of characters, you have a stream of more logical units, like strings, numbers and other symbols.
The tokenizer is fairly simple, it cares about very localized regions of the input.
We have an enum for denoting all possible token types:
enum class TOKEN
{
CURLY_OPEN,
CURLY_CLOSE,
COLON,
STRING,
NUMBER,
ARRAY_OPEN,
ARRAY_CLOSE,
COMMA,
BOOLEAN,
NULL_TYPE
};
We have a token struct that encapsulates the token and its value. Tokens like ARRAY_CLOSE do not have a value, but the STRING token contains the value as the actual string.
struct Token
{
std::string value;
TOKEN type;
std::string toString()
}
The Tokenizer class has this structure:
class Tokenizer {
std::fstream file;
size_t prevPos;
public:
Tokenizer(std::string fileName);
auto getWithoutWhiteSpace();
auto getToken();
auto hasMoreTokens();
void rollBackToken();
}
It has a helper function getWithoutWhitespace which just gets us the next character after skipping all the whitespace and newlines.
auto getWithoutWhiteSpace()
{
char c = ' ';
while ((c == ' ' || c == '\n'))
{
file.get(c); // check
if ((c == ' ' || c == '\n') && !file.good())
{
// std::cout << file.eof() << " " << file.fail() << std::endl;
throw std::logic_error("Ran out of tokens");
}
else if (!file.good())
{
return c;
}
}
return c;
}
We also have a helper named rollBackToken. The rollBackToken function goes back to the previous token. We store the position of the previous token in prevPos.
void rollBackToken()
{
if (file.eof())
{
file.clear();
}
file.seekg(prevPos);
}
The actual body of the getToken function is also fairly simple.
For getToken, the logic is:
-
For characters like ‘[’, ‘,’, ‘]’, ‘{’, ‘}’, we just map it to the corressponding enum type
-
The special case is when we encounter either ‘"’ or a number. In both cases the logical unit is the whole string or the whole number. So in case of string, we keep consuming characters till ‘"’ is reached and for numbers, till we run out of consecutive number characters. We then store the string / number in the “value” field of the token.
auto getToken()
{
// string buf;
char c;
if (file.eof())
{
std::cout << "Exhaused tokens" << std::endl;
// throw std::exception("Exhausted tokens");
}
prevPos = file.tellg();
c = getWithoutWhiteSpace();
struct Token token;
if (c == '"')
{
token.type = TOKEN::STRING;
token.value = "";
file.get(c);
while (c != '"')
{
token.value += c;
file.get(c);
}
}
else if (c == '{')
{
token.type = TOKEN::CURLY_OPEN;
}
else if (c == '}')
{
token.type = TOKEN::CURLY_CLOSE;
}
else if (c=='-' || (c >= '0' && c <= '9'))
{
//Check if string is numeric
token.type = TOKEN::NUMBER;
token.value = "";
token.value += c;
std::streampos prevCharPos = file.tellg();
while ((c=='-')||(c >= '0' && c <= '9') || c == '.')
{
prevCharPos = file.tellg();
file.get(c);
if (file.eof())
{
break;
}
else
{
if ((c=='-')||(c >= '0' && c <= '9')||(c=='.'))
{
token.value += c;
}
else
{
file.seekg(prevCharPos);
// std::cout << c << std::endl;
}
}
}
}
else if(c=='f'){
token.type = TOKEN::BOOLEAN;
token.value = "False";
file.seekg(4, std::ios_base::cur);
}
else if(c=='t'){
token.type = TOKEN::BOOLEAN;
token.value = "True";
file.seekg(3, std::ios_base::cur);
}
else if(c=='n'){
token.type = TOKEN::NULL_TYPE;
file.seekg(3, std::ios_base::cur);
}
else if (c == '[')
{
token.type = TOKEN::ARRAY_OPEN;
}
else if (c == ']')
{
token.type = TOKEN::ARRAY_CLOSE;
}
else if (c == ':')
{
token.type = TOKEN::COLON;
}
else if (c == ',')
{
token.type = TOKEN::COMMA;
}
return token;
}
NOTE: that here we’re mapping to boolean or null as soon as we encounter “f” (false) or “t” (true) or “n” (null). Ideally, we should validate whether the characters after are also matching. If it is “faklse”, for example, then it should give an error.
Parsing
The parser class is structured as:
class JSONParser {
std::fstream file;
std::shared_ptr<JSON::JSONNode> root;
std::unique_ptr<JSON::JSONNode> current;
Tokenizer tokenizer;
public:
JSONParser(const std::string filename) : tokenizer(filename) {}
void parse();
std::shared_ptr<JSON::JSONNode> parseObject();
std::shared_ptr<JSON::JSONNode> parseString();
std::shared_ptr<JSON::JSONNode> parseNumber();
std::shared_ptr<JSON::JSONNode> parseList();
std::shared_ptr<JSON::JSONNode> parseBoolean();
std::shared_ptr<JSON::JSONNode> parseNull();
};
The root refers to the root of the JSON tree, and current refers to the node currently being parsed.
Parse Function
Now as for the parser, here’s the basic logic:
- CURLY_OPEN -> We’re parsing a JSON object, call parseObject to parse object
- ARRAY_OPEN -> We’re parsing a JSON array, call parseArray to parse array
- STRING -> We’re already given the string value by the tokenizer, we just have to assign it to a JSONNode.
- NUMBER, BOOLEAN, NULL_TYPE -> Similar case as STRING
Initially, root will be null and we’ll assign it the initial JSONNode.
This is implemented in the parse function:
void parse() {
std::string key = "";
while (tokenizer.hasMoreTokens()) {
Token token;
try {
token = tokenizer.getToken();
std::cout << token.toString() << std::endl;
switch (token.type) {
case TOKEN::CURLY_OPEN: {
std::shared_ptr<JSON::JSONNode> parsedObject = parseObject();
parsedObject->printNode(0);
if (!root) {
root = parsedObject;
}
break;
}
case TOKEN::ARRAY_OPEN: {
std::shared_ptr<JSON::JSONNode> parsedList = parseList();
//parsedList->printNode(0);
if (!root) {
root = parsedList;
}
break;
}
case TOKEN::STRING: {
tokenizer.rollBackToken();
std::shared_ptr<JSON::JSONNode> parsedString = parseString();
//parsedString->printNode(0);
if (!root) {
root = parsedString;
}
break;
}
case TOKEN::NUMBER: {
tokenizer.rollBackToken();
std::shared_ptr<JSON::JSONNode> parsedNumber = parseNumber();
//parsedNumber->printNode(0);
if (!root) {
root = parsedNumber;
}
break;
}
case TOKEN::BOOLEAN: {
tokenizer.rollBackToken();
std::shared_ptr<JSON::JSONNode> parsedBoolean = parseBoolean();
//parsedBoolean->printNode(0);
break;
}
}
}
catch (std::logic_error e) {
break;
}
}
// assert token not valid
}
Now let us look at parseObject, parseList and parseString. The implementations of parseNumber, parseBoolean and parseNull are quite similar to parseString so they aren’t covered explicitly. However, you can check them out in the Github Repo.
Parse List
In parseList, what we’re basically doing is this:
- First token is ARRAY_OPEN
- Second token should be of the JSON value and should indicate whether it is an object, a list, number, boolean or null. Corressponding to that, we call the appropriate parsing function.
- The next token should either be COMMA or ARRAY_CLOSE. If it is COMMA, we have another JSON value to parse. If it is ARRAY_CLOSE, then we’re done.
std::shared_ptr<JSON::JSONNode> parseList() {
std::cout << "Parsing List" << std::endl;
std::shared_ptr<JSON::JSONNode> node = std::make_shared<JSON::JSONNode>();
JSON::JSONList *list =
new JSON::JSONList();
bool hasCompleted = false;
while (!hasCompleted) {
if (!tokenizer.hasMoreTokens()) {
throw std::logic_error("No more tokens");
} else {
Token nextToken = tokenizer.getToken();
std::shared_ptr<JSON::JSONNode> node;
switch (nextToken.type) {
case TOKEN::ARRAY_OPEN: {
node = parseList();
break;
}
case TOKEN::CURLY_OPEN: {
node = parseObject();
break;
}
case TOKEN::STRING: {
tokenizer.rollBackToken();
node = parseString();
break;
}
case TOKEN::NUMBER: {
tokenizer.rollBackToken();
node = parseNumber();
break;
}
case TOKEN::BOOLEAN: {
tokenizer.rollBackToken();
node = parseBoolean();
//parsedBoolean->printNode(0);
break;
}
case TOKEN::NULL_TYPE: {
node = parseNull();
break;
}
}
list->push_back(node);
nextToken = tokenizer.getToken();
if (nextToken.type == TOKEN::ARRAY_CLOSE) {
hasCompleted = true;
}
}
}
node->setList(list);
return node;
}
NOTE : There is some code duplication of the parsing logic between parse, parseList and parseObject. I’ll later refactor this out.
Parse Object
For parseObject, the logic is:
- First token is CURLY_OPEN
- Next token should be a string (the key) = The next token should be ‘:’
- The next token should be a JSON value. Like in parseList and parse, we delegate the parsing to the appropriate parsing function and then use the JSON node it returns. We then add this JSON node to the map with the above key.
- Next token is either COMMA or CURLY_CLOSE. If it is COMMA, we have another entry to parse. If it is CURLY_CLOSE, we’re done.
std::shared_ptr<JSON::JSONNode> parseObject(){
std::cout << "Parsing object " << std::endl;
std::shared_ptr<JSON::JSONNode> node = std::make_shared<JSON::JSONNode>();
JSON::JSONObject *keyObjectMap = new JSON::JSONObject();
bool hasCompleted = false;
while (!hasCompleted) {
if (tokenizer.hasMoreTokens()) {
Token nextToken = tokenizer.getToken();
std::string key = nextToken.value;
std::cout << key << std::endl;
tokenizer.getToken();
nextToken = tokenizer.getToken();
std::shared_ptr<JSON::JSONNode> node;
//std::cout << nextToken.toString() << std::endl;
switch (nextToken.type) {
case TOKEN::STRING: {
tokenizer.rollBackToken();
(*keyObjectMap)[key] = parseString();
break;
}
case TOKEN::ARRAY_OPEN: {
(*keyObjectMap)[key] = parseList();
break;
}
case TOKEN::NUMBER: {
tokenizer.rollBackToken();
(*keyObjectMap)[key] = parseNumber();
break;
}
case TOKEN::CURLY_OPEN: {
(*keyObjectMap)[key] = parseObject();
break;
}
case TOKEN::BOOLEAN: {
tokenizer.rollBackToken();
(*keyObjectMap)[key] = parseBoolean();
//parsedBoolean->printNode(0);
break;
}
case TOKEN::NULL_TYPE: {
(*keyObjectMap)[key] = parseNull();
break;
}
}
nextToken = tokenizer.getToken();
if (nextToken.type == TOKEN::CURLY_CLOSE) {
hasCompleted = true;
break;
}
} else {
throw std::logic_error("No more tokens");
}
}
node->setObject(keyObjectMap);
return node;
}
parseString is very simple, it just needs to map the token type to a JSONNode.
std::shared_ptr<JSON::JSONNode> parseString() {
std::cout << "Parsing String" << std::endl;
std::shared_ptr<JSON::JSONNode> node = std::make_shared<JSON::JSONNode>();
Token token = tokenizer.getToken();
std::string *sValue = new std::string(token.value);
node->setString(sValue);
return node;
}
That’s it, we have all the basic elements of a JSON parser!
Back to JSON
Since we have a JSON node that represents our JSON document, let us try going the other way. This’ll help us to also verify whether the JSON is parsed correctly.
The JSONNode::toString function takes in an indentation level. It is the amount by which to offset the child contents.
We first make a spaceString, which is a string with the number of space characters controlled by the indentation level.
Then, we check our current node type:
- STRING -> Output directly
- NUMBER -> Output directly
- BOOLEAN -> Output directly
- NULL -> Output directly
- Array -> Output ‘[’. Then call toString again for each JSON value, outputting either ‘,’ or ‘]’ after depending on whether it is the last JSON value
- Object -> Output ‘{’. Then the key, then ‘:’, then append the output of toString for the corressponding jsonValue. Then output ‘}’
std::string toString(int indentationLevel) {
std::string spaceString = std::string(indentationLevel, ' ');
//sstreams
std::string outputString = "";
// // std::cout < type << std::endl;
switch (type) {
case Type::STRING: {
outputString += spaceString + *values.s;
break;
}
case Type::NUMBER: {
outputString += spaceString + std::to_string(values.fValue);
break;
}
case Type::BOOLEAN: {
outputString += spaceString + (values.bValue ? "true" : "false");
break;
}
case Type::NULL_TYPE: {
outputString += spaceString + "null";
break;
}
case Type::LIST: {
// std::cout << "[";
outputString += spaceString + "[\n";
int index = 0;
for (auto node : (*values.list)) {
outputString += node->toString(indentationLevel + 1);
if (index < (*values.list).size() - 1) {
outputString += ",\n";
}
index++;
}
outputString += "\n" + spaceString + "]\n";
break;
}
case Type::OBJECT: {
outputString += spaceString + "{\n";
for (JSONObject::iterator i = (*values.object).begin();
i != (*values.object).end(); i++) {
outputString += spaceString + " " + "\"" + i->first + "\"" + ": ";
outputString += i->second->toString(indentationLevel + 1);
JSONObject::iterator next = i;
next++;
if ((next) != (*values.object).end()) {
outputString += ",\n";
}
outputString += spaceString + "\n";
}
outputString += spaceString + "}";
return outputString;
}
}
}
NOTE: For a more efficient implementation, we should take in a stream and output there. This is memory inefficient.
I ran the parser on a sample JSON, and below is the output after stringifying it from our internal structure.
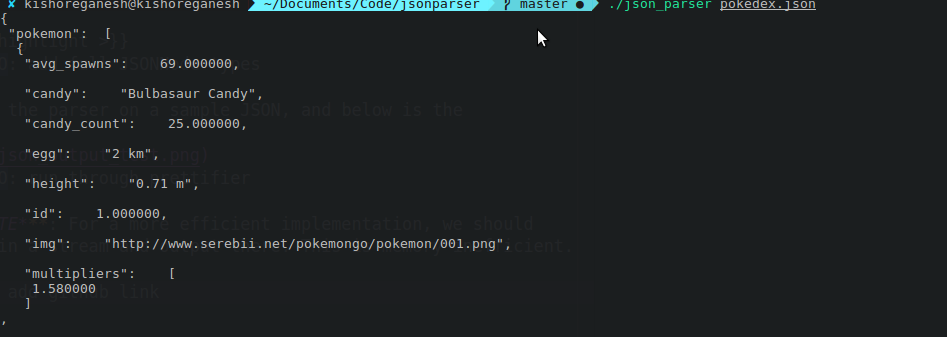
Its indentation is a bit janky. I should probably get around to fixing that sometime :).
I discussed the most important bits and pieces, but if you want to know what it looks like as a whole, you can check out the Github Repo. I would love it if you can help improve it!