Are Ubuntu APT repositories wasting space?
Sometime back, I went into a deep rabbit hole. This is a documentation of what I found. Consider the Ubuntu APT repository. I’m using the bionic-backports one.
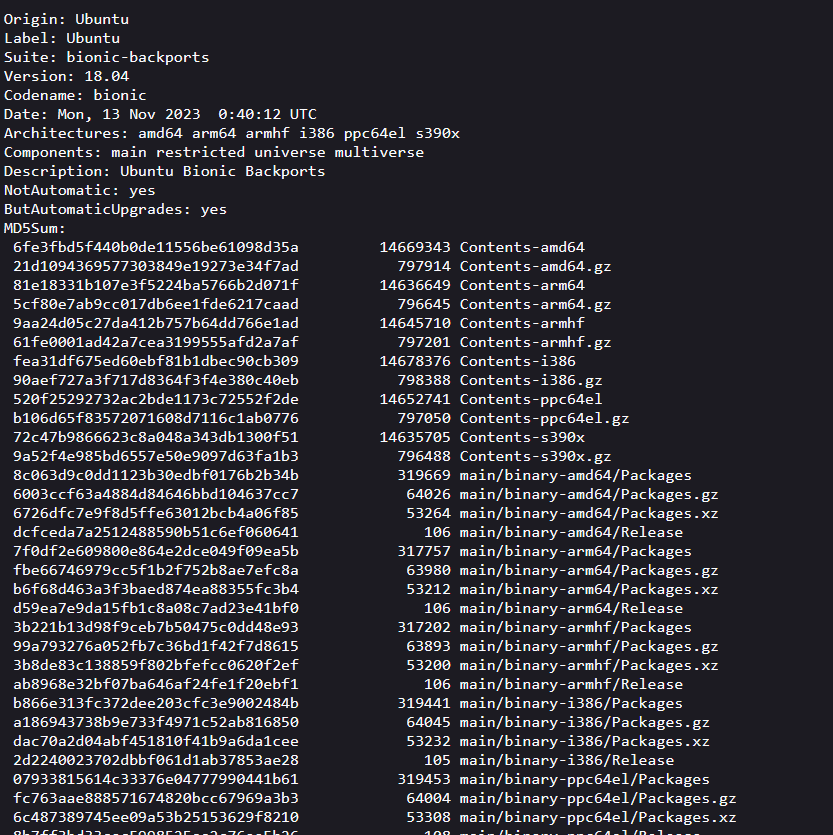 Each APT registry contains a ‘Release’ file which is an index of all the files in the repository. There are files listed with their associated archive files (a ‘.gz’ and a ‘.xz’ archive).
Each APT registry contains a ‘Release’ file which is an index of all the files in the repository. There are files listed with their associated archive files (a ‘.gz’ and a ‘.xz’ archive).

Somehow I wondered what gzip options are used to create the archives. Let us focus on the gzip archive (’.gz’) for now. I extracted the Packages from the Packages.gz present in the repository & attempted to recompress it using a quick gzip -k Packages.
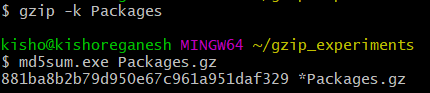
The md5sum didn’t match. What is it we’re missing? I decided to investigate this further on a smaller file.
 Thankfully, there seemed to be 0 byte files in the ‘Release’ file which seemed easier to inspect. I don’t know much about the motivation behind it, but they exist presumably to actively indicate that a certain file doesn’t exist. Obviously, the hashes of all archives of zero byte files are the same.
Thankfully, there seemed to be 0 byte files in the ‘Release’ file which seemed easier to inspect. I don’t know much about the motivation behind it, but they exist presumably to actively indicate that a certain file doesn’t exist. Obviously, the hashes of all archives of zero byte files are the same.
Are the gzip headers 40 bytes? A quick Google search revealed that a minimal gzip overhead1 is merely 20 bytes (header + empty DEFLATE block + checksum+ file size). This piqued my curiosity - where are the extra bytes coming from?
I first tried the default command: gzip emptyfile. This yielded an archive of size 31 bytes. That in itself was weird - wasn’t the overhead supposed to be just 20 bytes?
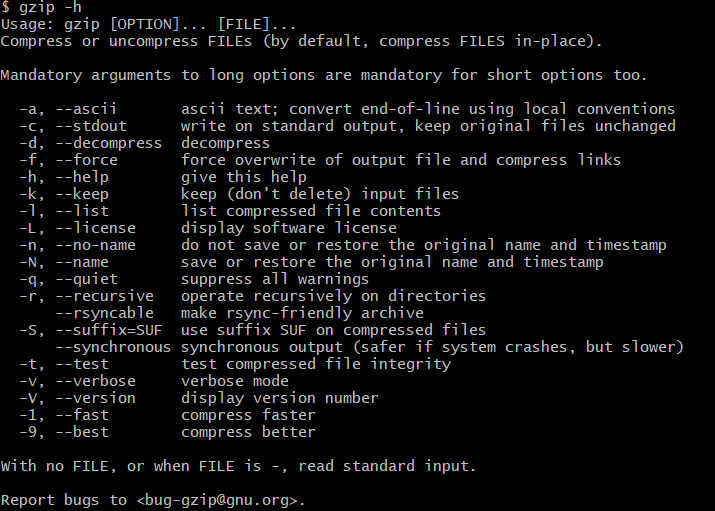 Then I discovered that gzip has many other options that may influence the size. So I tried various options:
Then I discovered that gzip has many other options that may influence the size. So I tried various options:
-n- this makes gzip not store the filename & timestamp in the archive: this was 20 bytes-r- this makes it ‘rsyncable’. It looks like this option is used for making the archive ‘rsync’ friendly (which allows you to just send the diff of changes instead of the whole thing). This was also 31 bytes
Clearly, none of them is yielding a 40 byte archive. I tried various different gzip versions to see if that changes anything, but the checksum remained consistent across versions. I then looked at the archive from the package repository in a hex editor to see what the content could be.
![]()
Ah - something weird is going on. The 0x1f8b is the magic number for gzip archives. It makes sense for it to be at the beginning of the file, but why is it at the end? And why is it the same sequence repeated - looking at the gzip format, it doesn’t seem to mandated by the gzip format.
Are these sequences present in all files?
![]()
Sure enough, they’re even present in an archive for a non-zero size file from the package registry. So somehow the gzip file contained a gzip header at the end of it? This seemed confusing - why doesn’t it give an error when you decompress it? That’s where an interesting feature of gzip archives comes in - you can concatenate them one after another. During decompression, gzip will extract all archives in the gz file. In this case, however, the second archive at the end is useless - when decompressed it is zero bytes.
This made sense, the ‘-n’ option to gzip produces an archive of size 20 bytes for an empty file. Concatenating two such archives together would mean an archive of size 40 bytes.
Sure enough, the following command executed twice creates an archive of size 40 bytes:
gzip -nkc empty_file >> empty_file.gz
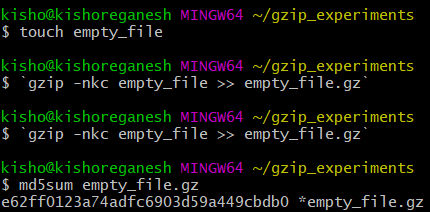
This has a checksum that matches what we see in the ‘Releases’ file for an archive compressing a 0 byte file.
However, if we do it for a non-zero size file, its hash doesn’t match the MD5Sum in the apt repositories file. Whilst it is true that there may be multiple ways to compress correctly using gzip, I have tried using random gzip versions, going all the way back to a 1992 release. The hashes are consistent across versions, so I’m not sure what is going on there. For reference, I used gzip -kn Package. I even tried varying the compression levels & --rsyncable, but they all yield archives of a different size from that in the Ubuntu repository.
UPDATE: I tried compressing using pigz which is a parallel implementation of gzip. I was able to get an archive of the right size & check sum using it.

I ran pigz -kn Package and then added in the empty archive at the end pigz -knc empty_file >> Package.gz.
Meanwhile, this surely seems like a bug, there’s an overhead of 20 bytes on all gzip files in the Ubuntu APT repository. Now an overhead of 20 bytes isn’t much but it certainly wasn’t a quirk I expected to run into :)
-
Google wasn’t very helpful about explaining the 20 byte overhead, but ChatGPT was. I wasn’t sure why it was 20 bytes, since the header + checksum + file size was just 18 bytes. ChatGPT explained that an empty DEFLATE block needs to be present ↩︎